
Formación LLM como servicio
Asistencia de expertos para ayudar a las organizaciones a entrenar o ajustar con seguridad grandes modelos de IA utilizando potentes recursos de superordenadores dedicados.

Se trata de un servicio personalizado basado en proyectos que incluye asesoramiento especializado, incorporación segura de datos, gestión de la formación y entrega del modelo final.
Este producto, adecuado para organizaciones que entrenan modelos básicos desde cero o para realizar ajustes a gran escala sobre datos propios protegidos, implica la reserva temporal y dedicada de una parte significativa del superordenador (por ejemplo, 128, 256, 512 o 1024 GPU) para un único trabajo de entrenamiento.
Compromiso directo
LLM Training as a service proporciona una experiencia premium totalmente gestionada, diseñada para organizaciones que necesitan precisión y fiabilidad. Incluye:
- Consultoría estratégica con expertos en la materia para definir objetivos, seleccionar arquitecturas y optimizar flujos de trabajo.
- Incorporación de datos segura y conforme a las normas, garantizando el cifrado, la privacidad y el cumplimiento de las normas reglamentarias.
- Orquestación integral de la formación, desde la asignación de recursos hasta la supervisión y resolución de problemas durante la ejecución.
- Validación y entrega de modelos completos, empaquetados para su despliegue con referencias de rendimiento y documentación.
Infraestructura dedicada
Su proyecto recibe acceso exclusivo a un entorno informático de alto rendimiento:
- Reserva temporal de 128-1024 GPUs en un cluster de supercomputación.
- Aislamiento garantizado para un rendimiento máximo, sin interferencias y previsible.
- Acceso a interconexiones de alta velocidad y almacenamiento optimizado para conjuntos de datos a gran escala.
Modelo de aprovisionamiento
- Asignación basada en proyectos, adaptada a objetivos y plazos de formación específicos.
- Sin arquitectura compartida o multiarrendamiento, ya que los recursos están totalmente dedicados a su carga de trabajo durante la duración del contrato.
Caso práctico
- Ideal para el desarrollo de modelos de cimentación personalizados, donde la escala y el control son fundamentales.
- Perfecta para LLM profundamente localizados, como los modelos lingüísticos africanos en sistemas de IA de dominios específicos que requieren una computación masiva y la supervisión de expertos.
Métrica básica
Precio todo incluido por GPU-hora para todo el clúster reservado y capacidades adicionales como almacenamiento, redes de alta velocidad entre el Centro de Datos del cliente y la Factoría de IA.
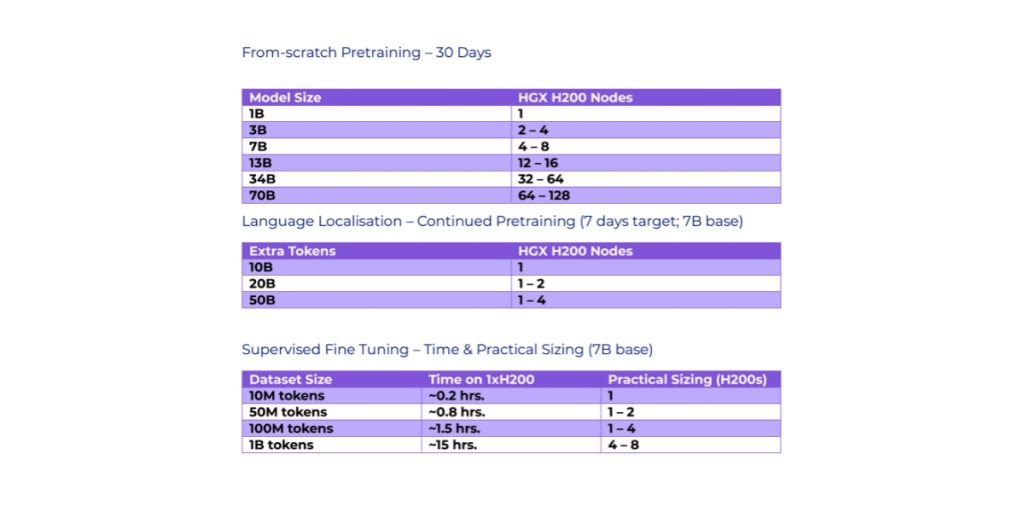
Requisitos ilustrativos de HGX H200 para la formación y localización de LLM (Confírmalo con NVIDIA)
Formación en modelos de visión por ordenador como servicio
CVMTaaS es una oferta especializada, basada en proyectos, diseñada para organizaciones que crean o ajustan modelos de visión por ordenador utilizando datos de imágenes propios. Este servicio admite tanto el entrenamiento básico de modelos como la adaptación a dominios específicos para tareas como la detección de objetos, la segmentación, la clasificación y la búsqueda visual.
Incorporación segura de datos
Admite conjuntos de datos visuales sensibles con controles de privacidad y conformidad.
Consulta de expertos
Reserva temporalmente una gran parte de un superordenador (por ejemplo, 128-1024 GPUs) para un único trabajo de entrenamiento.
Gestión de la ejecución de la formación
Aprovecha clusters de GPU dedicados y optimizados para cargas de trabajo de visión (por ejemplo, de 128 a 1024 GPU).
Entrega de modelos
Los modelos finales se entregan con referencias de rendimiento y formatos listos para su despliegue.
Empezar
Explore nuestras soluciones de IA para aprovechar todo el potencial de la transformación digital.
